성능 데이터 모델링
- 처음부터 데이터베이스 성능 향상을 목적으로 하는 작업
- 프로젝트 수행 중보단 사전에 철저하게 설계된 상태로 도입할수록 비용이 적게 듦
- 분석/설계 단계에서 성능 데이터 모델링을 수행할 경우 성능 저하로 인해 발생하는 재업무 비용 최소화

성능 데이터 모델링 고려사항
- 정규화를 정확하게 수행
- 데이터를 주요 관심사별로 분산
- 정규화를 통해 중복된 데이터가 쌓이는 것 막을 수 있음
- 데이터베이스 용량 산정 수행
- 어떤 테이블(엔터티)에 데이터 집중되는지 파악 가능
- 필요한 경우 테이블 분리와 조인을 통한 데이터 수집 필요
- 데이터베이스에서 발생되는 트랜잭션 유형 파악
- CRUD 매트릭스 혹은 시퀸스 다이어그램을 보면 파악하기 용이
- 데이터 조회에 필요한 조인 관계 등 파악 가능
- 데이터베이스의 용량과 트랜잭션 유형에 따라 반정규화 수행
- 테이블, 속성, 관계 등에 대해 포괄적인 반정규화를 통해 성능 조정
- 이력 모델, PK/FK, 슈퍼 타입/서브 타입의 조정
- 성능 우수한 순서대로 칼럼 순서 조정
- 성능 관점에서 데이터 모델 검증
- 항상 성능 최적화를 위해서 데이터 모델 검증
- 데이터 모델이 괜찮은 형태로 구조화 되어있어도 성능 최적화를 위한 선택을 위해 끊임없이 고민
정규화
- 데이터에 대한 중복성을 제거하여 성능을 향상시키는 것
- 특정 칼럼으로 분산되어 있는 데이터의 의미를 하나로 집약 ➡️ 테이블 칼럼 수 줄어들어 데이터 용량 줄일 수 있음
- 데이터의 일관성을 유지하고 데이터의 중복을 방지하며 데이터의 유연성을 유지하기 위해 데이터를 분해하는 과정

정규화 용어
| 정규화 | 이상 현상의 발생을 최소화하기 위해 작은 단위의 테이블로 나눠가는 과정 |
| 정규형 | 정규화된 결과물 |
| 함수적 종속성 | 테이블의 특정 칼럼 값(A)을 알고 있으면 다른 칼럼 값(B)을 알 수 있다고 가정할 때, B는 A에 함수적 종속성을 갖는다고 표현 |
| 결정자 | 함수적 종속성에서 A는 B를 결정짓는 요소기 때문에 '결정자'라고 표현 |
| 다치 종속 | 결정자 A에 의해 B의 값 다수를 알 수 있을 때, B는 A에 다치종속되었다고 표현 |
정규화 이점
- 데이터 유연성
- 종속성 강한 데이터를 분리하여 독립된 개념으로 정의 ➡️ 높은 응집도와 낮은 결합도 원칙에 충실
- 응집도 : 요소들이 서로 관련되어 있는 정도 (높을수록 품질 좋음)
- 결합도 : 요소들 간의 상호 의존하는 정도 (높으면 시스템 구현 및 유지보수 어려움)
- 종속성 강한 데이터를 분리하여 독립된 개념으로 정의 ➡️ 높은 응집도와 낮은 결합도 원칙에 충실
- 데이터 재활용성
- 정규화를 통해 데이터 개념이 조금 더 세분화 ➡️ 개념에 대한 재활용 가능성 증가
- 데이터 중복 최소화
- 식별자가 아닌 속성이 한 번만 포함 ➡️ 데이터 중복 최소화
정규화 유형
- 정규화는 함수적 종속성을 근거로 함

- 제1정규화
- 한 속성에 여러 개의 속성이 포함되어 있거나 같은 유형의 속성이 여러 개로 나눠져있는 경우 해당 속성 분리
➡️ 하나의 칼럼에는 하나의 속성만 포함 - 원자 값이 아닌 도메인 분해
- 한 속성에 여러 개의 속성이 포함되어 있거나 같은 유형의 속성이 여러 개로 나눠져있는 경우 해당 속성 분리


- 제2정규화
- 제1정규화를 만족시키고 PK가 아닌 모든 칼럼은 PK 전체에 종속
- PK에 종속되지 않거나 PK 일부 칼럼에만 종속되는 칼럼이 있다면 분리
- 부분적 함수 종속 제거
- 제2정규형 위반시 갱신 이상 현상이 발생할 가능성이 큼
- 갱신 이상 : 반복되는 데이터 중 일부를 갱신할 때 데이터가 일치하지 않는 문제

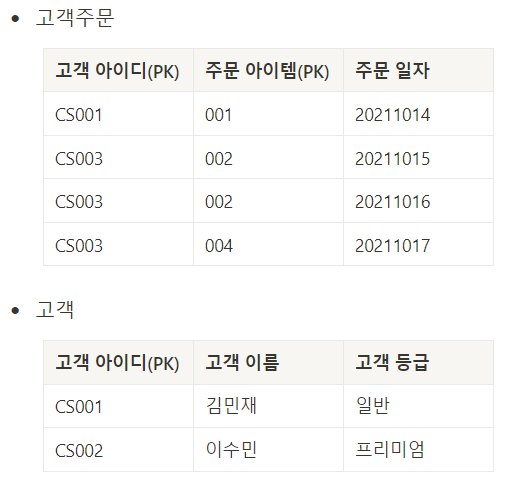
- 제3정규화
- 제2정규화를 만족시키고 일반 속성 간에도 함수 종속 관계 존재 X
- 이행적 함수 종속 제거


정규화 유형 정리
| 제1정규화 | - 모든 속성은 반드시 하나의 값을 가져야 함 - 그렇지 않을 경우 해당 속성 분리 (속성의 원자성 확보) |
| 제2정규화 | 주식별자에 완전하게 함수 종속되지 않은 속성을 분리하여 종속 관계 구성(부분 종속 속성 분리) |
| 제3정규화 | 일반 속성간의 함수 종속성 발생하지 않도록 분리(이전종속 속성 분리) |
| BCNF | 결정자 안에 함수 종속을 가진 주식별자 속성 분리 |
| 제4정규화 | 다치종속성 제거 |
| 제5정규화 | 조인 속성 제거 |
반정규화
- 정규화와 동일하게 '성능 향상'이라는 목적을 갖지만 데이터의 중복을 통해 목적을 달성
- 반정규화 적용하는 상황
- 데이터 조회 시 디스크 I/O량이 많아서 성능 저하되는 경우
- 테이블 간 경로가 너무 멀어 조인으로 인한 성능 저하 예상
- 칼럼을 계산하여 읽을 때 성능 저하 예상

🌟 반정규화 절차
- 반정규화 대상 조사
- 범위 처리 빈도수 조사
- 대량의 범위 처리 조사
- 통계성 프로세스 조사
- 테이블 조인 개수
- 다른 방법 유도 검토
- 뷰(View) 테이블
- 클러스터링 적용
- 인덱스 조정
- 응용 어플리케이션
- 반정규화 적용
- 테이블 반정규화
- 속성 반정규화
- 관계 반정규화
테이블 반정규화
- 테이블 병합
- 1:1 관계 테이블 병합 : 2개의 테이블을 하나의 테이블로 병합하여 조인 연산 제거
- 1:M 관계 테이블 병합 : 2개의 테이블을 하나의 테이블로 병합하여 조인 연산 제거
- 슈퍼/서브 타입 테이블 병합 : 슈퍼/서브 관계를 하나의 테이블로 병합하여 조인 연산 제거
- 테이블 분할
- 수직 분할 : 디스크 입력/출력을 분산 처리하기 위해 칼럼 단위의 테이블을 1:1로 분리하여 처리
- 수평 분할
- 행 단위로 집중 발생하는 디스크 입/출력 및 데이터 접근 효율을 높여 성능 향상시키기 위해 테이블 분리
- 하나의 테이블에 있는 특정 값을 기준으로 테이블 분할
- ex) 요금 납부 테이블을 년/월/일 테이블로 분할
- 테이블 추가
- 중복 테이블 추가 : 다른 업무이거나 서버가 다른 경우 동일한 테이블 구조를 중복하여 원격 조인 제거
- 통계 테이블 추가 : SUM, AVG, COUNT 등을 미리 수행하고 계산
- 이력 테이블 추가 : 이력 테이블 중에서 마스터 테이블에 존재하는 레코드를 중복하여 이력 테이블에 적용
- 부분 테이블 추가 : 특정 테이블에서 자주 조회하는 칼럼을 모아놓은 별도의 반정규화된 테이블 생성
칼럼 반정규화
- 중복 칼럼 추가 : 조인 연산으로 인한 성능 저하 방지를 위해 중복 칼럼 추가하여 조인 연산 수행 X
- 파생 칼럼 추가 : 트랜잭션이 처리되는 시점에 계산하는 값을 미리 계산한 칼럼 따로 구성
- 이력 테이블 칼럼 추가 : 많은 데이터 처리할 때 불특정한 날에 대한 조회나 최근 값을 조회할 때 나타날 수 있는 성능 저하를 예방하기 위해 이력 테이블에 칼럼 추가
- PK에 의한 칼럼 추가
- PK(복합키)를 단일 속성으로 구성한 경우 단일 PK 안에서 특정값을 별도로 조회하는 경우 성능 저하 나타날 수 있음
- 이때 이미 PK 안에 데이터가 존재하지만 성능 향상을 위해 일반 속성으로 생성
- ex) 주문번호(상품코드+주문일자) ➡️ 주문일자를 일반 속성으로 빼내고 주문일자 칼럼을 인덱스로 설정 - 응용 시스템의 오작동을 위한 칼럼 추가 : 비즈니스적으로 의미는 없지만 사용자 데이터를 처리하다가 잘못된 경우 원래 값으로 복구를 원할 때 이전 데이터를 임시적으로 중복하여 보관
관계 반정규화
- 중복 관계 추가
- 데이터 처리하기 위한 여러 경로를 거쳐 조인 가능
- 이때 발생할 수 있는 성능 저하 예방을 위해 추가적인 관계를 맺는 방법
'스파르타 코딩클럽 > [강의] SQLD 자격증 대비반' 카테고리의 다른 글
| [SQLD 자격증 대비반] 챕터 7. 관계형 데이터베이스와 DDL (0) | 2024.02.27 |
|---|---|
| [SQLD 자격증 대비반] 챕터 5. 데이터베이스 성능 (0) | 2024.02.22 |
| [SQLD 자격증 대비반] 챕터 3. 데이터 모델링의 요소 (0) | 2024.02.19 |
| [SQLD 자격증 대비반] 챕터 2. 데이터 모델링 (0) | 2024.01.02 |
| [SQLD 자격증 대비반] 챕터 1. SQL과 데이터베이스 (0) | 2023.12.18 |