결측치(Missing Value)
- 존재하지 않는 데이터
- 결측치 처리 방법
- 수치형 데이터
- 평균값 대치 : 대표적인 대치 방법
- 중앙값 대치 : 데이터에 이상치가 많아 평균값이 대표성이 없을 경우 중앙값 이용
- 범주형 데이터
- 최빈값 대치
- 사용 함수
- 간단한 삭제&대치
▪️ df.dropna(axis=0) : 행 삭제
▪️ df.dropna(axis=1) : 열 삭제
▪️ Boolean Indexing
▪️ df.fillna(value) : 특정 값으로 대치( ex. 평균, 중앙, 최빈값) - 알고리즘 이용
▪️ sklearn.impute.SimpleImputer : 평균, 중앙, 최빈값으로 대치
➡️ SimpleImputer.statistice_ : 대치한 값 확인
▪️ sklearn.imput.IterativeImputer : 다변량대치(회귀 대치)
▪️ sklearn.impute.KNNImputer : KNN 알고리즘을 이용한 대치
- 간단한 삭제&대치
- 수치형 데이터
타이타닉 데이터 결측치 처리 실습
import pandas as pd
titanic_df = pd.read_csv('파일경로')titanic_df.info()
# 결측치가 있는 행 모두 삭제
titanic_df.dropna(axis=0).info()
# Age에 결측치가 있는 행 삭제
cond3 = (titanic_df['Age'].notna())
titanic_df[cond3].info()
# fillna 이용한 대치
# 평균값 계산
age_mean = titanic_df['Age'].mean().round(2)
titanic_df['Age_mean'] = titanic_df['Age'].fillna(age_mean)titanic_df.info()
## SimpleImputer를 이용한 대치
from sklearn.impute import SimpleImputer
si = SimpleImputer()
si.fit(titanic_df[['Age']])# 대치값 확인
si.statistics_
## array([29.69911765])titanic_df['Age_si_mean'] = si.transform(titanic_df[['Age']])titanic_df.info()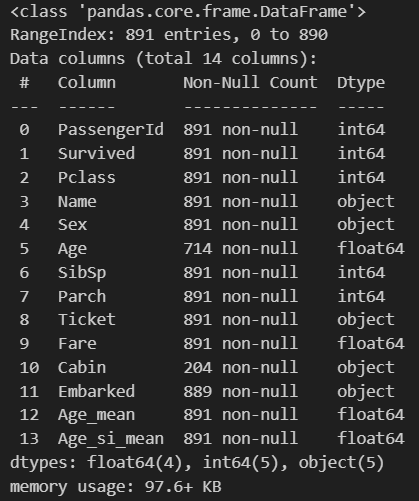
'스파르타 코딩클럽 > [강의] 머신러닝' 카테고리의 다른 글
| [머신러닝 심화] 데이터 분석 프로세스 - 데이터 분리 (0) | 2024.01.31 |
|---|---|
| [머신러닝 심화] 데이터 분석 프로세스 - 데이터 전처리(인코딩&스케일링) (0) | 2024.01.31 |
| [머신러닝 심화] 데이터 분석 프로세스 - 데이터 전처리(이상치) (0) | 2024.01.31 |
| [머신러닝 심화] 데이터 분석 프로세스 - 데이터 수집 및 EDA (0) | 2024.01.31 |
| [머신러닝 기초] 회귀와 분류 정리 (0) | 2024.01.30 |